平时做的应用,的确很少涉及非常具体的局部算法。不过最近一段时间还是遇到了一些,稍微整理一下,留个纪念。
产品的组合生成
举个例子,手机的颜色有黑白的,内存有16G,32G的,那么就有黑色16G,黑色32G,白色16G,黑色32G等组合项,
当然属性可能不止两项,想列出所有的组合项。
如果只有两种属性,很简单
1
2
3
for ( 属性 in 属性 1 )
for ( 属性 in 属性 2 )
// TODO 得到组合项
但是,如果有不定项的话,就不能这么写了。
这需要知道点回溯法的技巧,我是用了非递归的方式编写的 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public static List < List < String >> merge ( List < String >... ls ) {
int len = ls . length ;
int [] pos = new int [ len ]; //对i而言,表示第i种属性当前选择是哪个值
Arrays . fill ( pos , 0 );
String [] r = new String [ len ]; //存放待生成的组合项
List < List < String >> res = new ArrayList < List < String >>();
int k = 0 ; //当前正在遍历第几种属性
while ( k >= 0 ) {
while ( pos [ k ] < ls [ k ]. size ()) {
r [ k ] = ls [ k ]. get ( pos [ k ]);
if ( k == len - 1 ) { //是否已经是最后一个属性
// 找到一个组合项,复制到res里边去
pos [ k ] = pos [ k ] + 1 ;
} else {
k ++; //当前位置的属性已经选择,处理下一种属性
}
}
pos [ k ] = 0 ;
k --; //当前位置的属性已经遍历完,需要回溯到上一种属性去
if ( k > 0 ) {
pos [ k ] = pos [ k ] + 1 ;
}
}
return res ;
}
说真的,即使加了注释,没有相关的算法基础,也是不容易看清楚的,所以有同事看到这个写法,在大呼救命。
请求URL参数匹配
最近有需求,要对请求里边的参数做匹配,规则是这样的:
例如有下面三条规则(其中问号表示变量,参数的顺序没关系):
* User=?&Password=BB&CurrentTab=LOG&CurrentTab2=LOG
* User=?&Password=?&CurrentTab=LOG1
* User=?&Password=?&CurrentTab=LOG
如果请求参数是XX=222&User=Q&Password=BB&CurrentTab=LOG,则只能匹配第三条,因为第一条多一个参数,第二条的值是LOG1,对应不上。
有个非常简单的思路,就是把参数拆开,然后一个个匹配。但是由于业务的请求数非常大,担心对系统是否有影响。
于是,弄了个测试原型,开50个线程的线程池,跑500个任务,每个任务跑1w次,匹配3个配置项。整个框架代码是这样的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public void work () throws Exception {
final String match1 = "User=?&Password=BB&CurrentTab=LOG&CurrentTab2=LOG" ;
final String match2 = "User=?&Password=?&CurrentTab=LOG1" ;
final String match3 = "User=?&Password=?&CurrentTab=LOG" ;
ExecutorService pool = Executors . newFixedThreadPool ( 50 );
int tasksize = 500 ;
final CountDownLatch latch = new CountDownLatch ( tasksize );
long s = System . nanoTime ();
for ( int k = 0 ; k < tasksize ; k ++) {
pool . submit ( new Runnable () {
@Override
public void run () {
Random r = new Random ( 100000000 );
for ( int i = 0 ; i < 10000 ; i ++) {
String toMatch = "XX="
+ r . nextInt ()
+ "&User=AA&Password=BB&CurrentTab=LOG" ;
// TODO 测试toMatch
}
latch . countDown ();
}
});
}
latch . await ();
System . out . println ( System . nanoTime () - s );
}
先用最简单的方法来做基准测试,有时候最简单的方法就可以满足要求了,粗略的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
Map < String , String > matchs = new HashMap < String , String >();
String [] split = toMatch . split ( "&" );
for ( String mss : split ) {
String [] split2 = mss . split ( "=" );
matchs . put ( split2 [ 0 ], split2 [ 1 ]);
}
similar ( match1 , matchs );
similar ( match2 , matchs );
similar ( match3 , matchs );
....
private boolean similar ( String match , Map < String , String > matchs ) {
String [] ms = match . split ( "&" );
for ( String m : ms ) {
String [] split2 = m . split ( "=" );
if (! matchs . containsKey ( split2 [ 0 ]))
return false ;
if (! "?" . equals ( split2 [ 1 ])) {
if (! split2 [ 1 ]. equals ( matchs . get ( split2 [ 0 ])))
return false ;
}
}
return true ;
}
在我的机器上简单跑一下,大约要28s。这个算法非常暴力,用split和map结构搞定了。
如果用StringTokenizer的话,还能快些,我试了一下,把第一步split换了的话,大约需要25s.
我觉得这个效果也还是可以接受的。
下面再用纯手工操作字符串的方式,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
UrlMatcher matcher = new UrlMatcher ( toMatch );
matcher . match ( match1 );
matcher . match ( match2 );
matcher . match ( match3 );
class UrlMatcher {
private String toMatch ;
int [] pos = new int [ 20 ];
int ps ;
public UrlMatcher ( String toMatch ) {
int ss = 0 ;
this . toMatch = toMatch ;
int len = toMatch . length ();
int st = 0 ;
int ed = 0 ;
for ( int i = 0 ; i < len ; i ++) {
char c = toMatch . charAt ( i );
if ( c == '=' ) {
ed = i - 1 ;
pos [ ss ++] = st ;
pos [ ss ++] = ed ;
st = i + 1 ;
pos [ ss ++] = st ;
} else if ( c == '&' ) {
pos [ ss ++] = i - 1 ;
st = i + 1 ;
}
}
pos [ ss ] = len - 1 ;
ps = ( ss + 1 );
}
public boolean match ( String m ) {
int len = m . length ();
int st = 0 ;
int ed = 0 ;
int vs = 0 ;
int ve = 0 ;
for ( int i = 0 ; i < len ; i ++) {
char c = m . charAt ( i );
if ( c == '=' ) {
ed = i - 1 ;
vs = i + 1 ;
} else if ( c == '&' ) {
ve = i - 1 ;
if (! match2 ( m , st , ed , vs , ve )) {
return false ;
}
st = i + 1 ;
}
}
return match2 ( m , st , ed , vs , len - 1 );
}
boolean match2 ( String m , int st , int ed , int vs , int ve ) {
boolean ma = true ;
for ( int i = 0 ; i < ps ; i = i + 4 ) {
if ( pos [ i + 1 ] - pos [ i ] == ed - st ) {
int sst = st - pos [ i ];
for ( int j = pos [ i ]; j <= pos [ i + 1 ]; j ++) {
if ( toMatch . charAt ( j ) != m . charAt ( sst + j )) {
ma = false ;
}
}
if ( ma ) {
if ( ve == vs && '?' == m . charAt ( vs )) {
return true ;
} else {
if ( pos [ i + 3 ] - pos [ i + 2 ] == ve - vs ) {
int vst = vs - pos [ i + 2 ];
for ( int j = pos [ i + 2 ]; j <= pos [ i + 3 ]; j ++) {
if ( toMatch . charAt ( j ) != m . charAt ( vst + j )) {
return false ;
}
}
return true ;
} else {
return false ;
}
}
}
}
}
return false ;
}
}
代码比较粗糙,对某些情况不是很严格,但不影响总体的性能评测,这个逻辑不到2s,要快15倍以上 。
这个写法的特点是:使用数组而不是Map,使用标记位置而不是截取字符串,一次扫描。
不过,这个代码很粗糙,不要太当真。
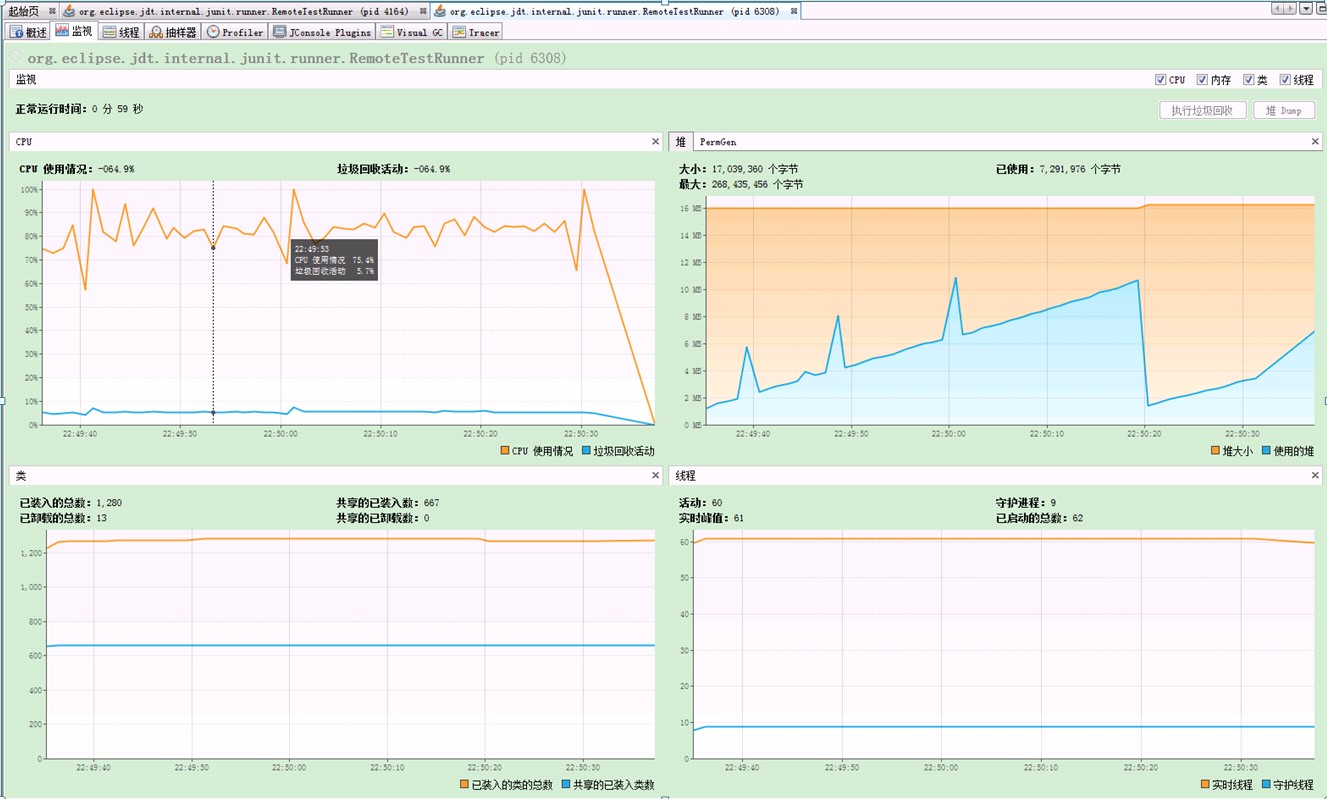
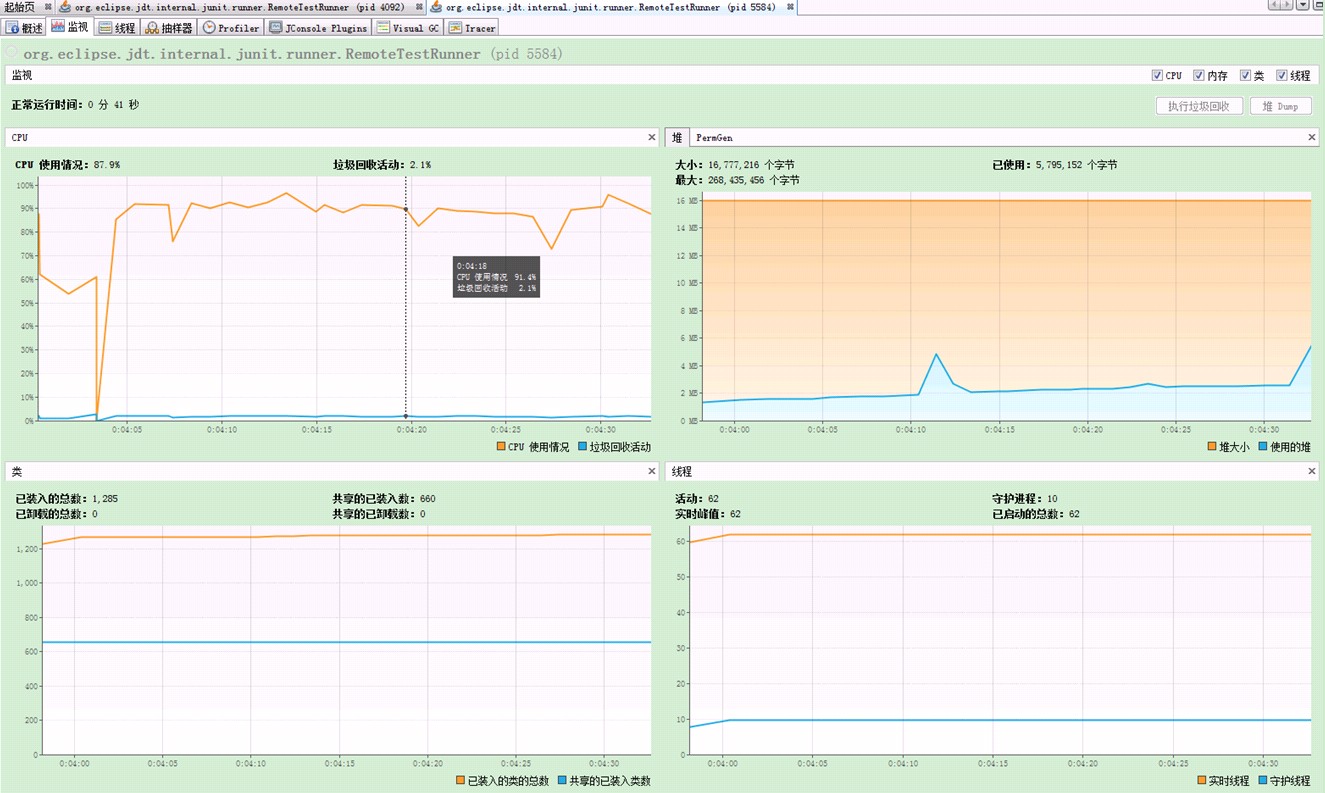
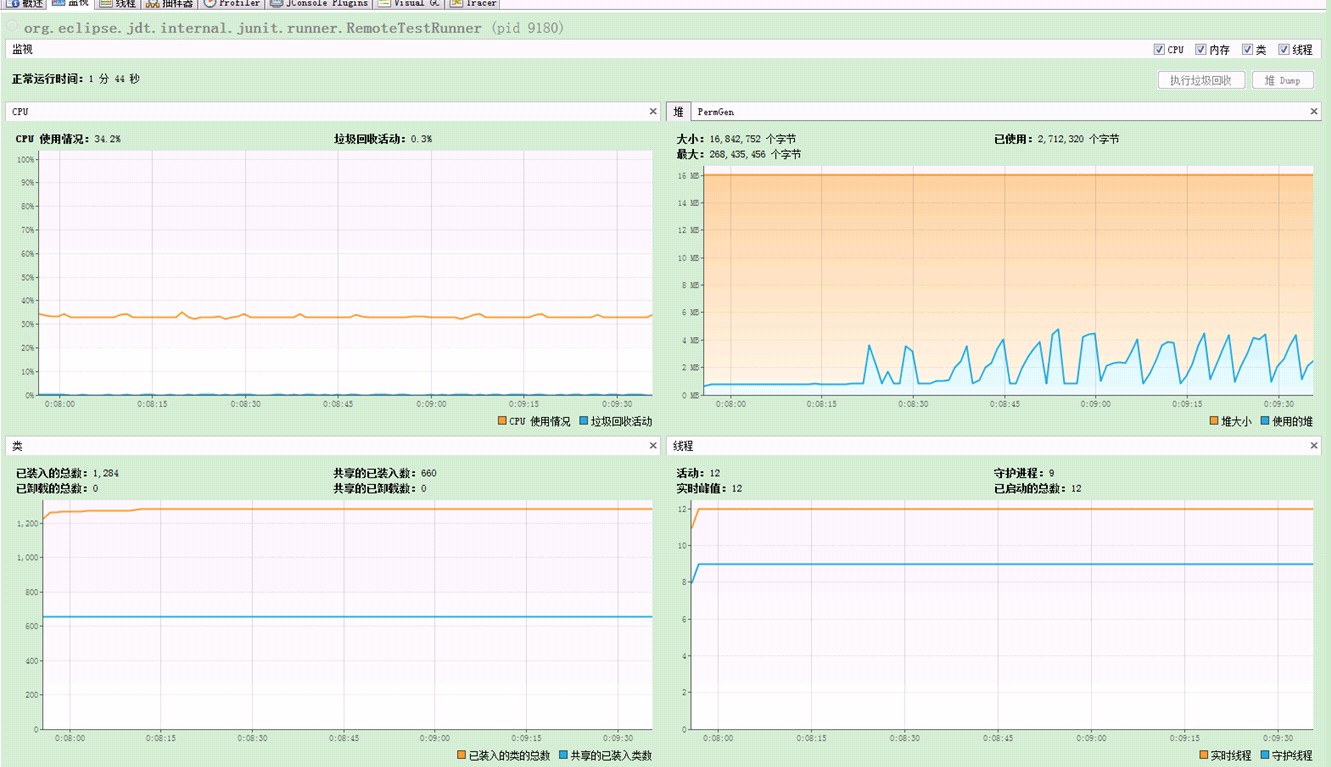
看看我机器上显示的虚拟机负载情况。
图1:最简单的做法
图2:手工打造,相对的内存消耗小些
图3:还是手工打造,不过单线程,相对来说CPU使用率就小很多了
小结
经常听到算法没什么用,算法没地方使用的论调,我也都一笑置之。
不过,我也承认,在现在的工作中,的确很少会直接面对非常具体的局部算法 。
但我还是不能赞同上面的观点,毕竟有些场景还是不得不考虑的 :
做不到,没有算法的支持,根本不知怎么写好
做不好,简单的实现没法满足,需要高效的算法